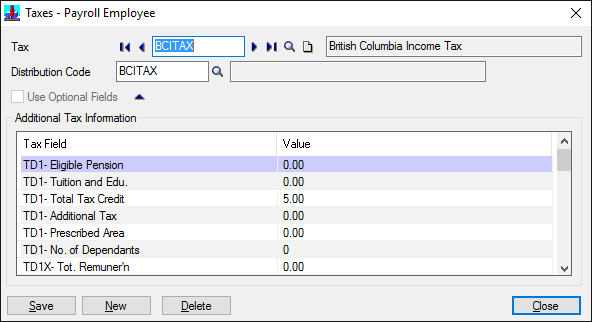
 Recording a macro didn’t really help as the mechanism the UI uses to identify each row is the PARMSEQ field, which is an incrementing value representing the row number of the table.
For an automated import this is quite brittle as an additional entry could potentially reorder the rows causing the incorrect row to be updated.
When viewing the table we found an integer value (PARMNBR) was being stored, which we could only assume was some sort of reference to the record.
Recording a macro didn’t really help as the mechanism the UI uses to identify each row is the PARMSEQ field, which is an incrementing value representing the row number of the table.
For an automated import this is quite brittle as an additional entry could potentially reorder the rows causing the incorrect row to be updated.
When viewing the table we found an integer value (PARMNBR) was being stored, which we could only assume was some sort of reference to the record.
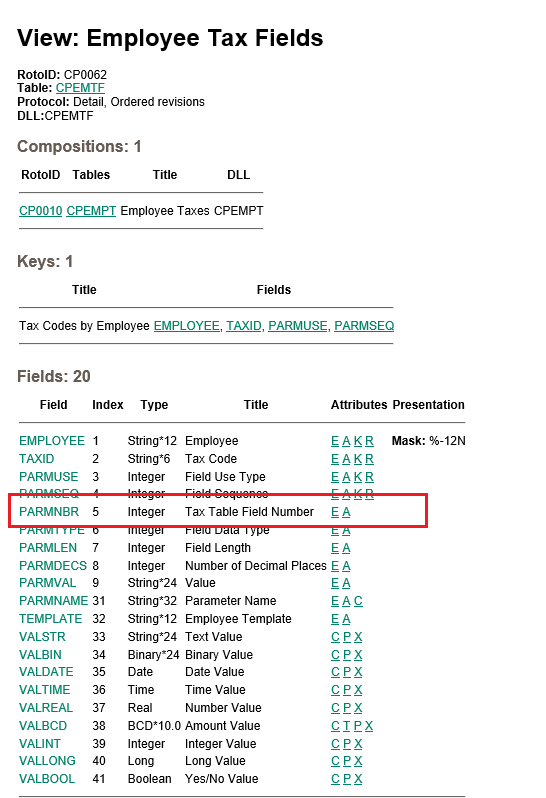 The PARMNMBR would be fine to use as the key to update, but you would need to know it’s value and this is a little concealed, ideally we’re looking to use the description as the key to update these values.
Investigation 1 (Fail)
Hunting around the tables….no tables would be found with this info.
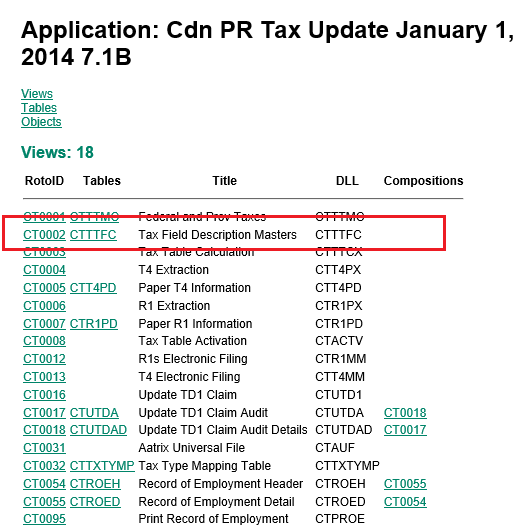
Investigation 2 (RVPSPY)
We opened our friend, RVSPY with nesting turned on and found the screen was calling CT0002.
The PARMNMBR would be fine to use as the key to update, but you would need to know it’s value and this is a little concealed, ideally we’re looking to use the description as the key to update these values.
Investigation 1 (Fail)
Hunting around the tables….no tables would be found with this info.
Investigation 2 (RVPSPY)
We opened our friend, RVSPY with nesting turned on and found the screen was calling CT0002.
 This makes sense since all descriptions are stored in resource files, so the PARMNBR was actually the Resource ID.
To get the description we needed to using the RscGetString method to retrieve them (note that we’re querying the CT module and not the CP application.
This makes sense since all descriptions are stored in resource files, so the PARMNBR was actually the Resource ID.
To get the description we needed to using the RscGetString method to retrieve them (note that we’re querying the CT module and not the CP application.
|
1 |
mDBLinkCmpRW.Session.RscGetString("CT", CT.Fields("PARMNBR").Value) |
Don’t think that all of your data is going to import every time, if you’re lucky some of it might some of the time.
When designing or writing your integration application it is essential that you expect errors and, as a result, design your program with the possibility for errors at the forefront of what you’re trying to achieve. In fact errors are probably just as critical as the data itself, if not more so.
This blog describes our best practices for designing error handling and logging within an integration.
Design Pattern – The Layered Approach to Error Handling
In a previous position I had the unenviable task of having to maintain several of a colleague’s poorly written import programs. Each time I made a modification I would re-factor a certain part of the program just for my own sanity and in conjunction I maintained several integrations I’d written myself. Over time each import converged to a similar structure, all based upon the way the integration handled errors.
The resulting pattern was a 3, sometimes 4, layer structure where each layer had its own error handling responsibilities.

- Atomic transaction: This is the inner most layer of your integration and is responsible for managing a single ‘atomic’ transaction. On failure it is this layer which cancels or rolls-back any half written transaction.
- Transaction handler: The transaction handler is essentially a loop which calls into the ‘atomic’ transaction handler. When the atomic handler raises an error, this layer needs to decide how to proceed: whether to move to the next transaction or abort.
- Task handler (optional): When your integration interfaces with anything more than a single end-point the task handler manages the handling of exceptional and non-exceptional data. Where a transaction succeeds, it needs to be submitted to the next end-point, whereas a failure usually means that it should not be processed at the next.
- Entry point: The outermost layer to your application. It is responsible for:
[inner-list list=”1″] [inner-list-el double=”1″]Generation of the end user log or processing report.[/inner-list-el] [inner-list-el double=”1″]Catching and logging any unexpected or catastrophic errors.[/inner-list-el] [/inner-list]
Atomic transactions
It goes without saying that whenever an error occurs in your automated integration it shouldn’t leave half written, partial transactions, database records, or files.
Sometimes however the concept of a transaction needs some thought, and requires input from business requirements, the technology of the platform and the ability to re-process data.
For example, should a batch of cash transactions into an accounting system be imported in an all-or-nothing approach, or should the integration import the ones it can, omitting the erroneous transactions? This scenario has implications on where the batch is posted; without the erroneous transactions, it may affect the bank reconciliation function at a later point.
Logging types
In our experience there are two audiences for the logs of any integration: end-users and technical staff. Users will want something they can understand, and technical people want something they can use to debug or understand a problem.
End-user reports
- Are sent to the people responsible for monitoring any integration/data feed.
- Should be in readable, easily digested format.
- Should allow the user to be able to quickly reconcile data passed between applications.
- Should provide the user enough information to allow them to identify and/or resolve the issue, or at least identify any erroneous data.

Catch all & Catastrophic error logging
- Used to catch unexpected errors and exceptions, useful for technical staff to help identify isolated issues.
Catastrophic errors are simply those you didn’t plan; for example, a loss of network connection; a corrupted file; a sudden disconnection from a database; an untimely permissions change; or out of memory exception.
In contrast, an invalid item code on a sales order import is not catastrophic; it should be handled by your standard logging mechanism and reported on your end-user reports. - These errors should be logged locally to either a local file or local database, windows event log. Don’t rely on remote resources such as remote databases or email as network availability could be limited or the cause.
Runtime logging
Errors, warnings & messages should be persisted as early as possible, which means writing to a database or file as and when they occur. Should a catastrophic error occur you have a process log, a trace, which would otherwise be lost if they were held in memory and persisted at the end of the process.
Log libraries
It is worth mentioning that there are a number of open source logging and tracing libraries available such as nlog, log4net, the .net trace libraries and Microsoft’s Enterprise framework which can provide you with a robust and feature rich way for persisting errors and warnings to a number of mediums. If you decide to use these, as opposed to rolling-your-own log scheme, the libraries can require some understanding to configure & setup and their outputs are not suited for end users.
Generating the end user process report
At the conclusion of processing it is necessary to generate the process report for the end users. If you’ve followed our recommendations, this should mean re-querying the medium to which the errors were persisted during processing and re-formatting them into an easy to read format.
The best and easiest format to send the end users a process report is email for the following reasons:
- Everyone has email.
- Portable and amendable: Annotations can be made and forwarded to others if remedial action needs to be made by another person.
- Logs can be easily formatted with html and presented nicely.
Summary
Error handling and logging is a key component of any application, more so with integration! Without proper error logging and reporting, your organisation will at best spend needless time resolving and reconciling data between applications and at worst lose customers because of poor service and lost transactions.
We hope this has been of use to some of you and if you ask us nicely, we may just provide you with some samples and template code illustrating the best practices we’ve described.
File transfer
The old school method for data exchange has existed for as long as computers have interchanged data. File transfer involves one application creating a file and putting it in an agreed location, whilst the receiving application reads, processes and then does something with the file. Pros- Secure: File transfer can be easily locked down, making it a relatively secure means to exchange data. FTP and SSH are both solid protocols meaning remote exchange over the internet is secure.
- Difficult to audit: Compared with other mechanisms files typically don’t have any natural means to audit or to trace audit.
- Remote servers require an FTP/SSH solution to exchange files, adding another chink in the chain of events.
- Fragile: Easy to get out of sync where a failure can require significant manual intervention to re-establish normal operation.
- CSV and other column based formats such as fixed width text and Excel suffer from brittleness, where file schema modifications (field additions and deletions) require significant re-configuration on the receiving end.
- One transaction per file: It’s much easier to identify a particular transaction, and re-processing is easy should something go awry.
- For CSV and other column based formats, always add new fields to the end of the file; never remove existing ones, better still don’t use these formats!
- Use a resilient API based data format such as Xml or JSON. Do not go overboard however.
- Try to avoid Xml schema where possible. We feel schemas add unnecessary constraints to the format, where a substantial amount of the inherent flexibility of the format is lost. They add a level of complexity not required in the SME space.
- Always use a recognised API/library when consuming and producing Xml/JSON data. This will at minimum ensure the format is standard compliant. We’ve seen several instances where organisations (that should know better) provide us with improperly escaped Xml, simply because they weren’t using an API to produce the Xml.
- After files are processed move them to an archive directory; don’t delete.
Database & staging tables
Our preferred means for both integration and synchronisation, the use of databases & staging tables providing a much more robust transport as compared to file exchange. Staging tables are an intermediate set of database tables where the sender records pending data for the recipient(s) to later process. Pros- SQL: Provides vendor and format independence to query and update a database and table schema(s) changes are usually non-breaking.
- Audit and Traceability: SQL/Databases provide an easy means to record and query any key data required for auditing purposes e.g. timestamps, error & warning messages.
- Durability and Recoverability: Databases are naturally durable and far less vulnerable to corruption. In the event of a failure recovery can be made quickly assuming a backup is available.
- Security: Where interchange take place over the internet the database needs to be open to the outside world leading to potential attacks. These can be mitigated by restricting the connecting IP addresses, use of complex passwords, amongst others.
- Always have the following fields in a staging table:
- Status: Used to record whether a record is pending or processed. Always include an error status which allows you to identify erroneous transactions quickly. It is recommended that an index is setup on the status field to help speed querying.
- Last Modified Date: A timestamp to record when the last update was made.
- Last Update By: Used to record which application made the last update.
- Reason/error/message: Where there’s an error or a warning generated as part of the integration or synchronisation it should be recorded against the original record. This then gives you a robust audit trail which can be used later to trace problems.
- Foreign Record Id: Where a recipient application generates a transaction or record id (such as an Order, Invoice, or even Customer number) update the staging table with this reference.
- Backup frequently: Depending on the volume of data or the location of the database i.e. for high volume sites or where the database is publicly accessible this may be several times a day.
- Always update the staging table immediately after writing to the destination application.
- Where processing takes a long time, consider setting the status field to an intermediate value to prohibit other integration processes from processing the same data.
Message queue
A message queue is a transport level asynchronous protocol where a sender places a message into a queue until the receiver removes the message to process it. One of the key attributes of a message queue, especially for data synchronisation, is that messages are guaranteed to be delivered in FIFO order. Message queues have traditionally been limited to larger scale integration and synchronisation and where both sender and receiver exist on the same network. However, with the explosion of cloud computing and an agreed standard (AMQP), there is an increasing prevalence of low cost services:
Message queues have traditionally been limited to larger scale integration and synchronisation and where both sender and receiver exist on the same network. However, with the explosion of cloud computing and an agreed standard (AMQP), there is an increasing prevalence of low cost services:
- Windows Azure Service Bus
- Amazon SQS
- Storm MQ: Currrently in-beta this ‘free’ service looks promising.
- FIFO: Messages are guaranteed to be delivered in order.
- Robust and Transactional: Message queues can be backed up, and are naturally transactional.
- Message Queues are a Transport: The data format of the message still needs to be agreed between sender and recipient.
- Use a flexible data format such as Xml.
- File and database recovery is well known, message queues less so. Understand how to administer your message queue technology and how to recover on the event of a failure.
- Prevent message build up by having an application which is constantly listening for incoming messages.
- Use different queues for each data flow; don’t try to multiplex multiple message types onto a single queue.
No interchange
In this scenario there is no intermediate data form, instead each application holds its pending data until the recipient application retrieves it. Unless an application specifically integrates with another this style of interchange requires some form of middleware to mediate the interaction since:- Each application has its own interface i.e. webservice or a COM/Java/.Net API.
- The data usually requires some transformation for it to ‘fit’ with the other.