Hierarchical Data
Introduction & IMan Hierarchical Data Handling
Hierarchical data is organised with headers above and details beneath, which allows for repeating parent-child relationships.
IMan's support for hierarchical data is thorough and pervasive: each Reader is capable of consuming hierarchical data; each transform & task provides intrinsic hierarchical data handling; the flatten and hierarchy transforms provide the means to manipulate data into and out of a hierarchical structure. See Destination Defined Data Structure to find out why this is required.
Example
A sales order where the header record contains customer information, the first child (order details) contains the items, and a third level contains lot or serial number data.
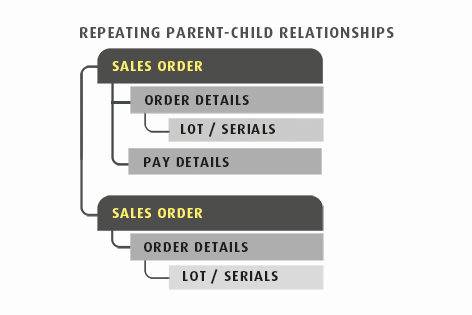
IMan's multi-level hierarchical data support permits it to handle everything from simple header-detail relationships e.g. invoices through to complex data structures such as a Project Setup in a Project or Job Costing system, a Multi-Level Bill Of Materials or complex transactions such as Purchase Order Receipts with Landed Costs.
Reader Support For Hierarchical Data
IMan provides the capability for consuming hierarchical data on each of its readers. The type of support provided varies on each of the data formats:
Naturally Hierarchical
This data has explicit relationships between parent and child.
The data formats supporting this style are Xml & JSON.
Any data provided by a connector reader will be provided in a hierarchical form.
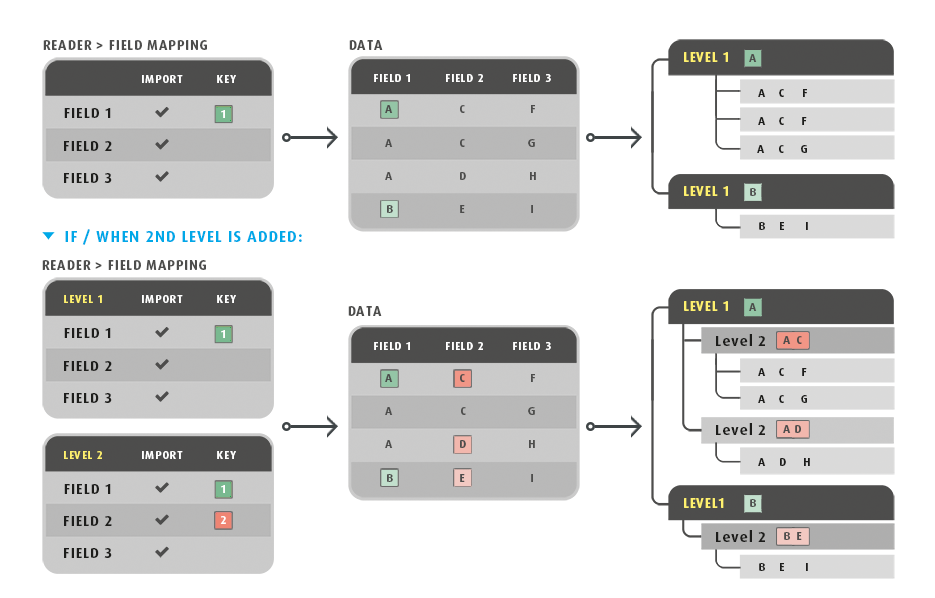
Keyed Hierarchy
A keyed hierarchy is on where there isn't an explicit relationship, but a relationship exists through common field values between records within a dataset.
In this style of hierarchy the fields expressing the relationship are identified through the Key Fields, where the values in one record relate to another.
This is supported by CSV, Database & Excel Readers and the same key concept is used when setting up the Hierarchy transform.
Key Fields
Key fields are used to construct the hierarchical dataset.
When setting up a hierarchy, the fields defining the relationship between the records are marked as keys by assigning them an incrementing numerical value. A record can be marked with one key field or multiple fields.
Child records are inserted into the dataset when the values of the fields marked as keys match those of its parent’s.
Since children are inserted to their parent using the values of the fields children do not necessarily need to follow immediately after their parent, however a child must not appear in the data before its parent.
When assigning the key fields, each child transaction must have at least one more key defined than its parent. An error will occur otherwise.
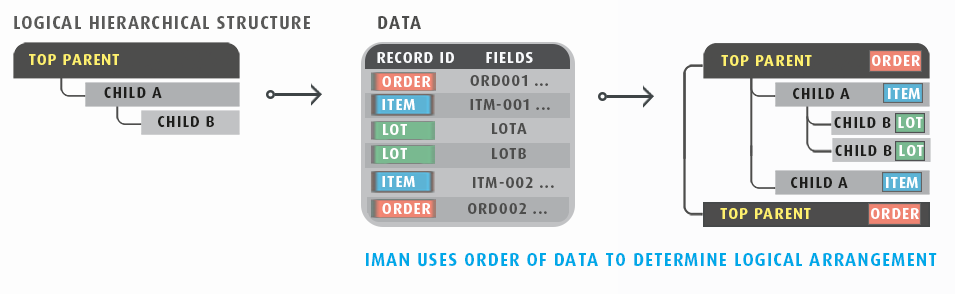
Ordered Hierarchy
An ordered hierarchy is one where the order of the records in the data infers the relationship.
The ordered hierarchy uses a 'Record Identifier' field to determine the record type.
When reading the data IMan identifies the relationship of the between records based on the Record Identifier field and the order of the data within the file.
Order Hierarchies require the data be presented in logical order (unlike Keyed Hierarchies) otherwise an error will occur.
The Ordered Hierarchy is supported by CSV, Excel & Fixed Width Readers.
Transform Support for Hierarchical Data
Each hierarchical 'level' is carried across from the previous transform's structure and the fields listed in the field mapping grid, changing the Transaction Type down changes the fields for the particular level.
The Hierarchy & Flatten transforms provide the means to manipulate data into & out-of hierarchical form.
Task Support for Hierarchical Data
Most tasks provide the means to work with hierarchical data through Expando fields, where the 'expanded' list of data is driven from the IMan data set.